上学期计算机网络综设自拟的题目,3个人的小组,由于比较简单,我一个人做完了。之前用过pyspider爬取过一些简单的东西,所以就用pyspider爬豆瓣小组帖子的回复作为数据源,然后在github里下载了一个1万多个词的敏感词库(https://github.com/observerss/textfilter)和一个百度找的几千词的敏感词库合并在一起作为这个工具的敏感词库。
敏感词过滤的具体实现方法就是用php载入词库,将词库字符串打散为数组,从数据源中匹配敏感词库的敏感词,匹配成功的就用特定的字符替换该敏感词(如:***)。
由于时间紧迫,前端部分采用bootstrap框架简单的编写。
pyspider这个爬虫框架带webui,操作方便,采集后的数据以json的格式显示,而且可以在线调试和直接下载数据,比较容易上手。
环境的安装过程就不一一细说了,可以百度、谷歌。
爬虫部分的代码:
- # -*- encoding: utf-8 -*-
- from pyspider.libs.base_handler import *
- class Handler(BaseHandler):
- crawl_config = {
- "headers": {
- "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
- "Accept-Encoding":"gzip, deflate, sdch",
- "Accept-Language":"zh-CN,zh;q=0.8",
- "Cache-Control":"max-age=0",
- "Connection":"keep-alive",
- "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" #模拟普通用户
- }
- }
- def __init__(self):
- self.base_url = 'https://www.douban.com/group/topic/85842259/?start='
- self.page_num = 1
- self.total_num = 5
- @every(minutes=24 * 60)
- def on_start(self):
- while self.page_num <= self.total_num:
- url = self.base_url + str(self.page_num)+'00'
- print url
- self.crawl(url, callback=self.detail_page)
- self.page_num += 1
- @config(age=10 * 24 * 60 * 60)
- def index_page(self, response):
- for each in response.doc('a[href^="http"]').items():
- self.crawl(each.attr.href, callback=self.detail_page)
- @config(priority=2)
- def detail_page(self, response):
- return {
- #"名字": [x.text() for x in response.doc('div.bg-img-green > h4 > a').items()],
- "评论": [x.text() for x in response.doc('div.reply-doc.content > p').items()],
- }
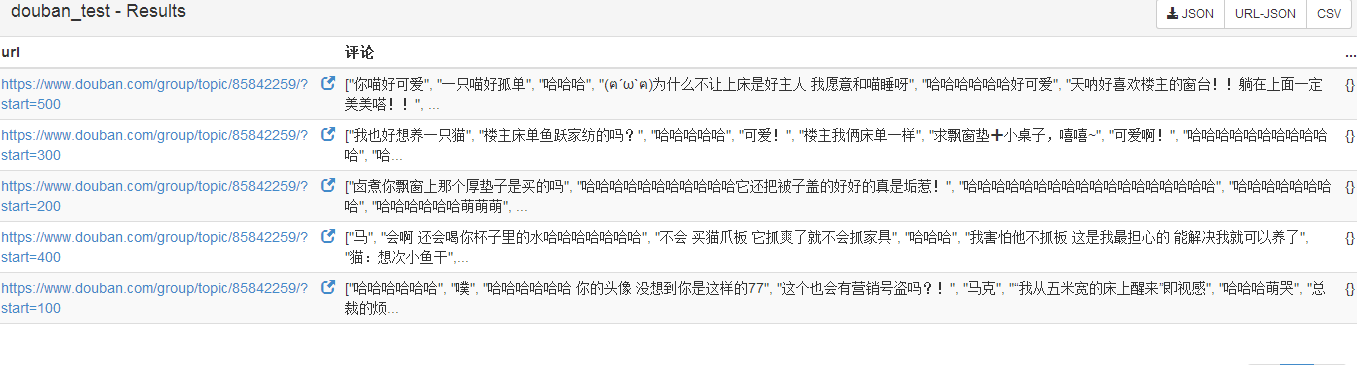
采集后的数据:
过滤的界面做的比较简单:
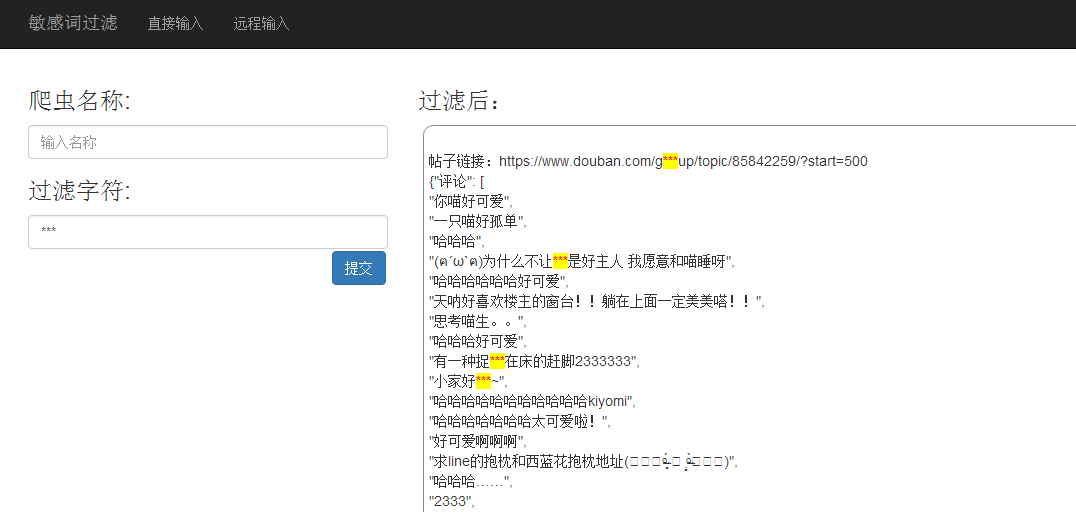
过滤后:
查看完整代码点此